La traducción y reciente publicación en Argentina del libro Lectura distante de Franco Moretti,1 publicado en inglés en el año 2013, constata el interés que viene generando el área de las humanidades digitales en América Latina. Moretti se ha convertido en una de las figuras visibles dentro del campo de los estudios histórico-literarios, en especial, después de publicar su afamado y en cierta medida polémico Graphs, Maps and Trees: Abstract Models for Literary History, en el cual propone el análisis cuantitativo de los textos literarios en periodos de larga duración. Moretti pretende trascender propuestas de lectura cercana (Close Reading) como el análisis de contenido2 y procura llevar los estudios literarios hacia los grandes volúmenes de texto al aplicar una lectura no literal sino cuantitativa de grandes volúmenes de información que permitan superar la interpretación y en cambio hacer evidentes estructuras, entendidas como repeticiones, regularidades, órdenes y patrones que se hacen visibles al percibir la literatura desde la longue dureé. En sus palabras: “the models I have presented [graphs, maps and trees] also share a clear preference for explanation over interpretation; or perhaps, better, for the explanation of general structures over the interpretation of individual texts”.3 Apreciaciones como las de Moretti constatan el sentido cuantitativo y no narrativo de ciertas tendencias en las humanidades digitales y ratifican el recelo por un posible enfoque neopositivista4 o por lo menos de una nueva versión de la cliometría, esta vez en forma de culturomics, un análisis cuantitativo de la cultura que busca fenómenos culturales perceptibles después de “minar” grandes volúmenes de libros digitalizados.5
A pesar de los esfuerzos de Moretti y su equipo del Standford Literary Lab,6 los resultados no han sido como esperaba, por lo menos así lo manifestó en una entrevista al diario argentino La Nación en la cual dijo: “Lo que tratamos de responder es si al estudiar grandes archivos de textos con estos nuevos métodos ha cambiado nuestra visión de la historia. Honestamente debo decir que, hasta ahora, eso no ha sucedido. Por eso, este método es por ahora más una promesa que una realidad”.7 Esta declaración de Moretti evidencia la dicotomía entre las capacidades de las aplicaciones informáticas y las posibilidades explicativas que se pueden derivar de su uso. No hay duda que con un algoritmo se podría “leer” una cantidad de textos más allá de la capacidad de cualquier ser humano, pero a pesar de su capacidad para extraer y relacionar contenidos aún no se ha encontrado la manera en que el programa entienda la forma del texto, por ejemplo, si las oraciones tienen un sentido literal o irónico.8
Después de una década de experimentación, el avance en el uso de herramientas informáticas para la lectura de datos masivos entre los historiadores es significativo, tal como se evidencia en la reciente publicación de Shawn Graham, Ian Milligan y Scott Weingart, Exploring Big Historical Data. The Historian's Macroscope.9
Hay que entender asimismo que para un historiador, como en general para cualquier humanista, tratar con datos masivos no significa lo mismo que para un analista de mercado u otro ingeniero que trabaja con big data. Siguiendo la explicación dada por Shawn Graham, los datos masivos pueden comprenderse como una cantidad de información más grande de lo que normalmente un investigador podría abarcar en su trabajo cotidiano;10 es decir, que es humanamente imposible leer e interpretar de manera tradicional.
Para el científico de las humanidades, el contenido de la información suele encontrarse de forma semiestructurada, es decir, catalogada de tal manera que es posible identificar el tipo de documento, las características físicas del original, el lugar de procedencia, autores, e incluso un resumen o descriptor del contenido; todo ello es lo que se denomina como metadatos, es decir, información que permite ubicar, ordenar y guardar datos de manera automatizada. Pero hay mucha información que no está estructurada y consiste en una inmensa colección de unidades de lenguaje para cuyo análisis no es posible fiarse de la automatización, por ello en muchas ocasiones se prefiere construir las bases de datos antes que “minar” los recursos Web para recolectar información útil para resolver los problemas planteados por las ciencias humanas. Así, las humanidades digitales se han enfrentado a lo que puede considerarse una nueva necesidad de lectura en el sentido de un novel paradigma de interpretación de textos históricos denominada la lectura distante.
Lectura distante
Una lectura distante es de hecho una no lectura, así definió Martin Mueller a la acción de permitir que las máquinas lean textos.11 Sin embargo, a pesar de la desafortunada concepción de la lectura automatizada como not-reading (años después Mueller modificó el término por Scalable Reading),12 su propuesta señala la consecución de un anhelo que ha estado presente desde hace mucho tiempo: la posibilidad de leer todos los libros del mundo. En términos prácticos implica quizás una aspiración más prosaica que consiste en superar la inevitable atadura a una disciplina acumulativa en la que los aportes más significativos al conocimiento son realizados por los más ancianos, tan arcaica es ante los ojos posmodernos nuestra ciencia.
El tiempo de lectura es inversamente proporcional a las exigencias productivas de la actual academia y en este factor puede radicar el interés que suscitan las formas de lectura digital, sin embargo, la propuesta de lectura cuantitativa con la aplicación de técnicas como la minería de datos y el análisis de contenido imponen retos a la misma manera en que leemos los textos. Un ejemplo práctico se puede observar al usar la herramienta Google Books Ngram Viewer, en la cual se puede “leer” la recurrencia de una frase en la totalidad de libros disponibles en Google Books por año y a través de un periodo de tiempo específico. En este caso, la no lectura de millones de libros en español brinda el siguiente resultado que se muestra en la figura 1.
FIGURA 1. N-grama por palabras en el lote de libros de Google Books
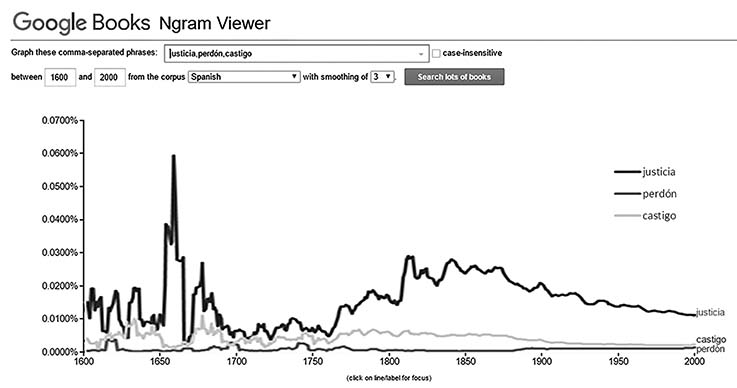
La figura 1 es una consulta simple que muestra las relaciones entre tres palabras que representan cada una un concepto: justicia, perdón y castigo. El ejercicio de leer el diagrama puede ser sencillo y podría reflejar un significativo interés por la “justicia” hacia la segunda mitad del siglo XVII y durante prácticamente los dos siglos que van de 1750 a 1950; la tarea por seguir podría ser explorar los lotes de libros de esos años o realizar operaciones combinadas entre n-gramas. Por ejemplo, si en lugar de buscar por cada concepto por separado realizamos la pesquisa de la relación entre justicia+castigo y justicia+perdón el resultado cambia significativamente como se observa en la figura 2.
FIGURA 2. N-grama por palabras relacionadas en el lote de libros de Google Books
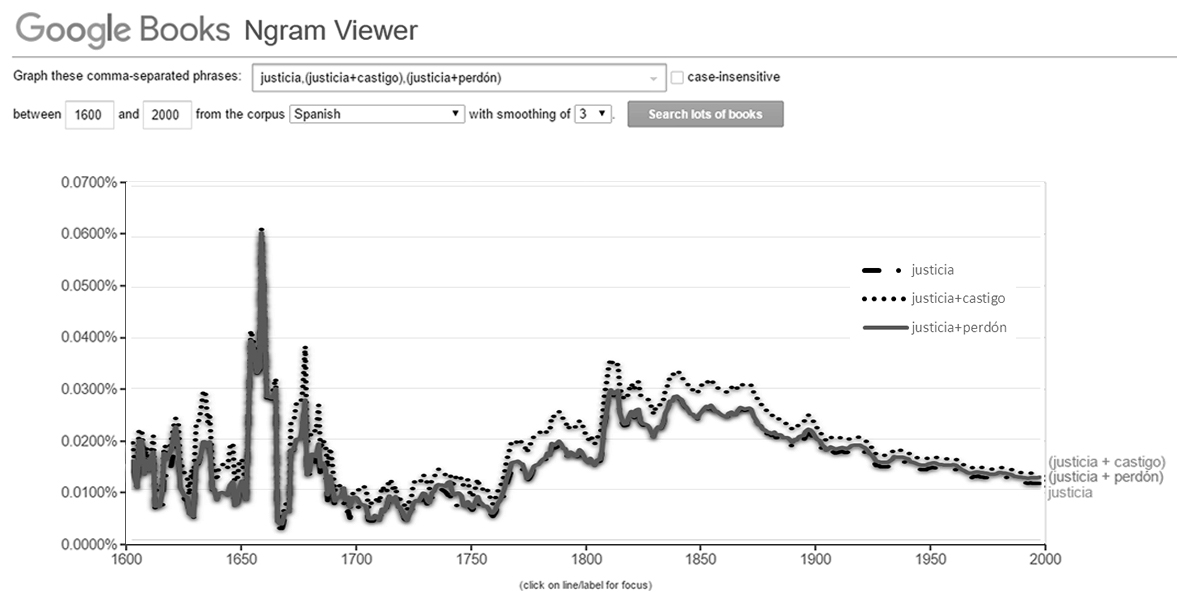
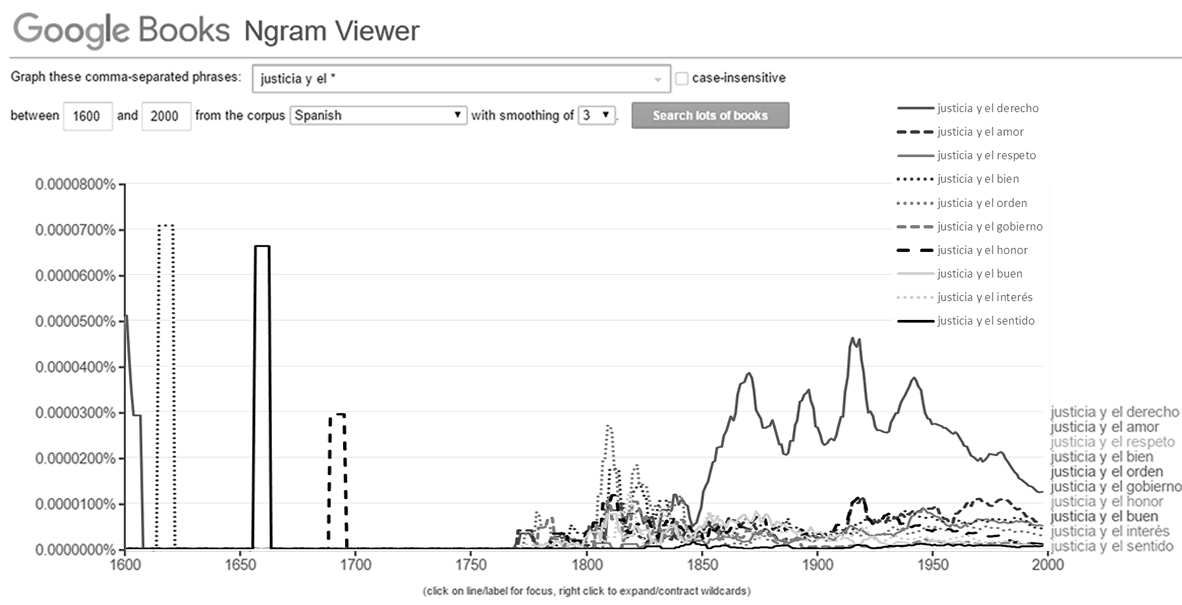
La similitud de ambas tendencias se debe a que la palabra dominante (justicia) se suma con la variable lingüística que se añade, en este caso perdón o castigo. Aunque son los mismos resultados que se obtuvieron para la figura 1, la lectura de esta gráfica hace más evidentes la importancia que se le brinda al castigo con relación a la justicia desde el siglo XVII hasta la primera mitad del siglo XX. Sin embargo esta lectura sigue siendo artificiosa ya que de alguna manera se lee lo que las variables quieren que se grafique (en otras palabras, el lector dirige los resultados de la lectura). Pero una muestra de lectura realizada por la máquina se puede observar con la aplicación de un “comodín”, esto es, un carácter especial que le indica a la máquina que debe realizar una lectura específica del corpus textual cuyo resultado es desconocido para el usuario lector. En la figura 3 se observa el uso de dicha técnica.
En este caso, figura 3, ya no es el lector quien indica a la máquina exactamente qué buscar sino es la máquina la que lee por el usuario e indica cuáles son las unidades de lenguaje más recurrentes en el lote de libros durante el tiempo consultado. Por ejemplo, me indica la presencia de la idea de “la justicia y el bien” en un lote de libros que va de 1613 a 1620, de “la justicia y el sentido” entre 1656 y 1661, y una interesante tendencia que inicia en 1768 y que terminará dominando hacia mediados del siglo XIX como es la frase “la justicia y el derecho”. Claramente esta “lectura” genera muchos interrogantes y campos de observación, como el periodo de 1770 a 1850, lo cual evidencia de alguna manera la eclosión de ideas que se vivió en el mundo hispanohablante en la época.
El ejercicio puede seguir durante horas, sin embargo, la posibilidad de llegar a explicaciones por vía de la máquina son limitadas. En primer lugar, no es posible la generación de n-grams con una longitud mayor a cinco unidades del lenguaje, es decir, difícilmente se alcanza a formar una frase y con ello interpretaciones más sesudas de las tendencias e ideas en el tiempo. Para ello se deberá descargar el Raw data puesto a disposición por Google y con ese insumo hacer análisis de gran escala.13
FIGURA 3: N-grama generado con el uso de un “comodín”
Otra opción es recurrir al topic modeling, esto es, definir “temas” con los cuales puedan hallarse sentidos “ocultos” en un gran contenido de texto. Un ejemplo de esta técnica se puede observar en el proyecto Mining the Dispatch (realizado por Robert K. Nelson, director del Digital Scholarship Lab en la universidad de Ritchmond) en el cual se observó la tendencia de ciertos temas en los textos publicados por el periódico Richmond Daily Dispatch que se evidenciaron gracias al uso del programa MALLET (MAchine Learning for LanguagE Toolkit).14 Gracias al uso de esta aplicación se encontró una serie de palabras que a su vez se pudo relacionar con contenidos específicos tales como anuncios, diatribas u opiniones, con los cuales fue posible trabajar para luego insertar los temas en un contexto social y narrativo. En todo caso Nelson es cauto respecto al uso del topic modeling y, en general, de la lectura distante, y dice al respecto: “topic modeling is certainly not a replacement for conventional, close reading methods. It and other distant reading methods do, however, provides historians an additional method that allows us to examine and detect patterns within not a sampling but in the entirety of an archive”.15
Es evidente que la lectura distante brinda una manera particular de “leer” la información digital que es imposible de abarcar por el humano tradicional, sin embargo, es importante mencionar que por el momento forma parte de la caja de herramientas de un porcentaje muy pequeño de especialistas. Entre más especializadas son las herramientas menos humanistas tienen la formación, el tiempo y la paciencia necesaria para entender un lenguaje tan ajeno al narrativo. A pesar de ello es claro que el uso de bases de datos y búsquedas es una acción cotidiana, tan sólo que dicha práctica se ha interiorizado de tal manera que parece natural que se hagan búsquedas en servicios para la comunidad científica y a partir de ello se realice un tipo específico de lectura fragmentada.
Lectura fragmentada
Como el mismo Moretti lo ha manifestado, la lectura distante es más un anhelo que una realidad. En un reciente artículo Lara Putnam16 llama la atención de que a pesar de las grandes herramientas analíticas que están disponibles para leer la información digital vía gráficas, mapas o árboles, la gran mayoría de humanistas (específicamente los historiadores) aún realizamos las pesquisas de información vía Google, Google Books, JSTOR, FamilySearch, entre otros lugares, en búsqueda de datos cualitativos, esto es por temas, personas, momentos o lugares. El digital turn en este sentido se convierte en una práctica cotidiana de los historiadores y humanistas de manera casi imperceptible, algo que ya había resaltado Anaclet Pons cuando dijo
todos nos hemos digitalizado de manera informal, de modo que escribimos con procesadores de texto, nos comunicamos por correo electrónico, consultamos información en los buscadores, etcétera. Sin embargo, tratamos ese mundo como si sólo fuese “un apéndice, una curiosidad, una distracción, algo superfluo”, que poco o nada tiene que ver con nuestro "verdadero trabajo".17
La crítica de Putnam consiste en señalar que el interés de las humanidades digitales, en especial, aquellos interesados en el trabajo con datos masivos, se ha centrado en el campo de lo posible (la lectura distante) en lugar de transformar lo más sencillo e informal: la búsqueda de información.18
Si la lectura distante y el modelado de datos plantean tantos problemas para el historiador y otros investigadores del campo de las humanidades ¿por qué aferrarse a lo posible antes que a lo ya alcanzado? Volviendo a Putnam, las búsquedas de información digital se han vuelto tan intuitivas que contrastan con la complejidad y cantidad de información disponible en repositorios masivos de información. Sin embargo, lo verdaderamente revolucionario no estaría marcado por el complejo modelado de datos desestructurados sino en el acercamiento al conocimiento transnacional gracias a la lectura desestructurada de información que, no sólo está descuadernada, sino que perdió su arraigo a un espacio nacional y se ancla ahora en el ciberespacio.19
Tal vez no exista duda acerca del cambio de escala de análisis temporal y espacial que configuró el aumento de recursos disponibles al investigador en la Web. Considero que la historia digital es ante todo una historia global20 y como tal debería ser la lectura realizada por el investigador. Es decir, las búsquedas por categorías cualitativas que se realizan diariamente expresan relaciones que son halladas de manera automática por el algoritmo de búsqueda. Además entre más complejo sea el algoritmo y mejor almacenada esté la información en el repositorio más evidentes resultarán dichas relaciones. De lo anterior surge un reto para los repositorios nacionales que consiste en lograr que los motores de búsqueda más avanzados puedan indexar su información o en su lugar mejorar las herramientas disponibles de búsqueda, lo cual es más complejo y sin duda requiere el trabajo de un equipo de desarrolladores especializados.
De manera cotidiana los investigadores estamos leyendo en red a través de buscadores y, por ende, lo hacemos de manera fragmentada. Cualquier estudiante está familiarizado con la lectura dispersa para la resolución de tareas en las cuales el buscador jerarquiza las fuentes según la pertinencia y cantidad de información disponible de acuerdo con una serie de palabras claves o preguntas recurrentes. Google Books hace la tarea incluso más sencilla al haber indexado el contenido completo de sus libros, lo cual permite señalar el lugar exacto en el que las categorías de búsqueda se encuentran ubicadas en cada libro, ordenando los resultados de acuerdo con la recurrencia de las claves marcadas en la pesquisa. De esta manera el buscador “lee” y selecciona por nosotros, quienes tenemos la tarea posterior de revisar la pertinencia de lo hallado a partir del contexto de las obras, ese pequeño paso que muchos estudiantes dejan de lado por el afán del copiar y pegar.
La lectura fragmentada no es una novedad, un estudio de 1999 realizado en la Universidad de Antioquia (Colombia) demostró que los estudiantes leían de manera literal y fragmentada debido al uso continuado de fotocopias,21 lo que se esperaría de alguna manera se viese superado por la accesibilidad a textos completos no se vio correspondido por una reacción docente a la lectura digital. Pero ésta no es una consecuencia de las fotocopias ni de la era digital, la lectura fragmentada, según Roger Chartier, fue favorecida por la popularización del códex y el desarrollo de nuevos gestos como el establecer índices, hojear el libro, citar pasajes, entre otros.22 Sin embargo, el texto descuadernado del mundo digital promueve una lectura aún más dispersa: “Esta lectura discontinua y segmentada que supone y produce, según la expresión de Umberto Eco, una ‘alfabetizzazione distratta’, es una lectura rápida, fragmentada, que busca informaciones y no se detiene en la comprensión de las obras, en su coherencia y totalidad”.23
Es bastante conocido el pasaje de Así habló Zaratustra donde el ermitaño señala que la sabiduría se consigue al rumiar (Wiederkäuen) los textos; para Nietzsche, el ritmo acelerado de la edad moderna impedía el ejercicio de pensar. En efecto, rumiar es cada día más complicado, si bien, las búsquedas permiten el acceso a miles de fragmentos que contienen una categoría (o concepto o frase) que los conecta. Dicha interconexión no se hace de manera consciente, aún más en sistemas como Google que por motivos empresariales se ven en la necesidad de ocultar sus algoritmos al usuario. Si las humanidades digitales contribuyen en este aspecto es precisamente en la “revelación” del código, sobre todo, porque la gran mayoría de los entusiastas de las digital humanities son promotores del código abierto, del acceso abierto, del software libre y del aprendizaje de lenguajes de programación.
La profundización en métodos de búsqueda relacional, no sólo en big data, sino en repositorios de cualquier dimensión, es una tarea que puede brindar efectos benéficos para la hermenéutica de textos históricos, sin embargo, no permitirá escapar, por lo menos en el corto plazo, a las tentaciones del anacronismo que una categoría aplicada en una línea de tiempo pueda generar. La interpretación es una actividad humana que hasta ahora no ha podido ser sistematizada, por lo cual se podría esperar que otras formas de lectura masiva con mayor intervención de actores conscientes podrían combatir la fragmentación textual de la era digital.
Lectura colaborativa
Otra de las innovaciones provenientes del campo de las humanidades digitales es el denominado crowdsourcing, otro término importado de la ingeniería de mercados en el cual varias personas vinculadas o externas a una empresa se comprometían voluntariamente a buscar la solución a un problema. En las humanidades el término ha mutado para comprender la vinculación de voluntarios en la ciencia, por ejemplo, subiendo documentos a la red, participando experiencias, e incluso colaborando con tareas como la transcripción de manuscritos.24 Los ejemplos más representativos de crowdsourcing se encuentran en proyectos como Wikipedia, el proyecto Gutenberg o el Internet Archive, los cuales surgen de iniciativas privadas sin ánimo de lucro, con una mayor capacidad de maniobra que una institución gubernamental o que un gigante industrial como Google.
Algunos investigadores han visto en el crowdsourcing una posibilidad para construir conocimiento. Una de estas iniciativas fue el proyecto What Do You Do With A Million Readers?, el cual surgió en respuesta a la pregunta problemática de Gregory Crane What Do You Do with a Million Books? La respuesta original de Crane consistió en que en caso de tener un millón de libros digitales lo más apropiado sería convertir los textos mediante un OCR, procesarlos al idioma deseado mediante un traductor automatizado y finalmente extraer la información mediante técnicas de minería de datos.25 La propuesta del grupo de la UCLA conformado por Roja Bandari, Timothy Tangherlini y Vwani Roychowdhury desarrolló una perspectiva diferente. Estos investigadores encontraron que las humanidades digitales se habían enfocado en explorar los recursos digitalizados por repositorios como Google Books mediante técnicas como la lectura distante, pero habían pasado por alto la explosión de lectores que comentan los libros en foros en línea y otros sitios de acceso abierto. En lugar de “minar” los libros lo hicieron con las reseñas voluntarias del sitio Goodreads para lo cual escogieron los cinco libros más populares (con más de 500,000 evaluaciones) de los cuales obtuvieron un estimado de 3,000 reseñas. El análisis de la información recolectada se hizo mediante la búsqueda de relaciones entre nombres, lugares, objetos y conceptos claves de cada novela (para lo cual se valieron de las guías de estudio SparkNotes). Finalmente fue posible encontrar algunas maneras en las que los lectores se relacionaban con la lectura sin que se pudiera llegar a conclusiones definitivas al respecto.26
Si bien, los resultados son nuevamente preliminares brindan otra estrategia de acercamiento a la lectura de grandes volúmenes de información, claro está, cuando es posible incentivar la retroalimentación por parte del público. Tal vez el feedback sea un problema manifiesto en nuestro contexto ya que en caso de tener un millón de lectores no necesariamente significa una misma cantidad de comentarios. Para traer a colación un proyecto particular, en el año 2012 construimos junto a Miguel Darío Cuadros un sitio titulado “Archivo de publicidad colombiana 1800-1950”,27 el cual surge ante la cierta popularidad que contaban algunos grupos en Facebook que compartían anuncios publicitarios que los administradores hallaban en los periódicos y revistas que guardaban en sus hogares. La idea consistía en conformar un repositorio con anuncios que difícilmente podían tener los usuarios en sus casas y por ello decidimos convocar a la comunidad de estudiantes, historiadores y aficionados a la historia para que compartieran aquellos avisos publicitarios que encontraran en medio de sus pesquisas hemerográficas. A través del tiempo pudimos acumular entre algunos colaboradores una pequeña cantidad de anuncios (211 en total), de los cuales requeríamos dos tareas básicas: transcribir y describir. De nuevo recurrimos a la comunidad a través de diferentes canales pero, con excepción de la contribución de la historiadora María Fernanda Erazo Obando y del equipo de trabajo del proyecto, no hubo otra contribución significativa.
El caso del Archivo Histórico de Publicidad tal vez no sea representativo de la generalidad de proyectos de historia digital en América Latina, pero sí permite evidenciar la dificultad que existe para lograr la contribución voluntaria del público y la comunidad académica, ambos capturados por las redes sociales. La evaluación que se hace en este aspecto es que a pesar del humilde avance de las humanidades digitales la relación con las aplicaciones digitales se encuentra aún en un nivel de consumo. El profesor de periodismo Dennis Jerz brinda una definición interesante de las humanidades digitales que ataca directamente este asunto: “We apply technology because we must participate in digital culture in order to understand it. Full participation in digital culture means contributing to (creating) the cultural economy, not simply observing (consuming)”.28
Es evidente asimismo que los repositorios institucionales no están contribuyendo a la generación de una cultura de lectura colaborativa ya que casi ninguno contiene un módulo de trabajo colectivo, ya sea del tipo Scripto que permite la transcripción voluntaria de documentos29 o tan sencillos como casillas de comentarios, foros de discusión o espacios para reseñas. El feedback, por lo general, se encuentra encasillado en las redes sociales (Facebook y Twitter de preferencia) o en los comentarios de soporte que no están disponibles al público; esto hace que exista una relación unidireccional, muy en el sentido del “servicio al cliente”, pero no en la generación de un crowdreading. La construcción de propuestas de lectura colectiva de fuentes, de interpretación de documentos y el análisis de esa participación “masiva” es definitivamente un campo que puede ampliar significativamente la perspectiva de la historia digital y de las humanidades digitales en general,30 aprovechando un comportamiento desarrollado en la Web 2.0 (la necesidad de participar, comentar, reaccionar y compartir) y así superar el brindar repositorios anclados en la Web estática.31
Lecturas, no lecturas, interpretaciones, narrativas
Si algo queda en evidencia en este ensayo es que la historia y las humanidades digitales han brindado una nueva problematización a la hermenéutica histórica, algo que de cierta manera se había dejado como ejercicio de los filósofos y que, gracias a los giros lingüístico y digital, se ha devuelto al campo de discusión del humanista. Es complejo, sin embargo, desembarazarse de la sospecha de positivismo que subyace en las formas de lectura de las humanidades digitales, más cuando autores como Franco Moretti prácticamente eliminan la posibilidad interpretativa de los textos en pos de unas ciencias humanas más cercanas a las ciencias duras. Sin embargo, esto no es más que un espejismo y los débiles resultados de la experimentación cuantitativa así lo demuestran hasta ahora. Lo que es realmente relevante son las nuevas formas de lectura y, por lo tanto, de interpretación que brinda el mundo digital.
Scott B. Weingart señala que la posibilidad de que la historia digital brinde nuevas explicaciones a viejas preguntas o genere nuevas preguntas está limitada en gran medida a las condiciones que se presentan desde el plano institucional. En ciertas ocasiones lo que lograría la historia digital es llegar a los mismos resultados con un método diferente, algo que señala Weingart genera cierta reticencia a los métodos computacionales por no brindar “nuevas conclusiones” (aunque paradójicamente ratifica viejas respuestas).32 Sin embargo, ¿es la historia digital un medio para la narrativa histórica o es en sí misma una nueva narrativa? Es difícil saberlo aún, la mayoría de acercamientos a este campo se han hecho desde el plano metodológico o como una adaptación de la lógica de la ingeniería a la investigación histórica, pero todavía no queda claro cómo puede contribuir a los elementos no narrativos de formación de sentido histórico y con ello contribuir a una crisis paradigmática que pueda llevar a nuevas preguntas y, en consecuencia, a reinterpretaciones de relato histórico.33
De cierta manera los historiadores y humanistas digitales nos encontramos como los inquisidores de la biblioteca de Babel, proponiendo métodos para desvelar los secretos de ese hexágono infinito que aunque no es el universo sí contiene una parte muy importante de lo que fuimos y somos como especie. Como el eterno viajero que atraviesa la biblioteca en cualquier dirección, hallamos al final que las posibilidades de encontrar patrones son inconmensurables y a la vez finitas, y en cada viaje algorítmico por los corredores, escaleras y hexágonos de la red nos topamos con “el mismo desorden (que, repetido, sería un orden: el Orden)”.34